Download Tool
Page Contents
- Purpose and Capabilities: what the Download tool does and why it's useful
- Usage Methods: how to use the tool across different platforms and programming languages
- Downloading from URL Lists: instructions for batch downloading papers from URLs
- Zotero Integration: comprehensive guide for using the Zotero Download functionality
- Best Practices: recommendations for effective use of the Download tool
- Troubleshooting: solutions to common Download tool issues
- Workflow Integration: how the Download tool fits into your systematic review process
Purpose and Capabilities
The prismAId Download tool is designed to streamline the literature acquisition phase of your systematic review. It offers two primary functionalities:
- URL-based Downloads: Batch download papers from a list of URLs for efficient collection of literature.
- Zotero Integration: Direct access to papers stored in your Zotero library or group collections.
This tool bridges the gap between literature identification and analysis by automating the tedious process of gathering papers, allowing you to focus on the review itself rather than manual collection tasks.
Usage Methods
The Download tool can be accessed through multiple interfaces to fit your preferred workflow:
Binary (Command Line)
# For URL list downloads
./prismaid -download-URL path/to/urls.txt
# For Zotero downloads (requires a TOML config file)
# First create a file zotero_config.toml with:
# user = "your_username"
# api_key = "your_api_key"
# group = "Your Collection"
./prismaid -download-zotero zotero_config.toml
Go Package
import "github.com/open-and-sustainable/prismaid"
// Download from URL list
err := prismaid.DownloadURLList("path/to/urls.txt")
// Download from Zotero
err := prismaid.DownloadZoteroPDFs("username", "apiKey", "collectionName", "./papers")
Python Package
import prismaid
# Download from URL list
prismaid.download_url_list("path/to/urls.txt")
# Download from Zotero
prismaid.download_zotero_pdfs("username", "api_key", "collection_name", "./papers")
R Package
library(prismaid)
# Download from URL list
DownloadURLList("path/to/urls.txt")
# Download from Zotero
DownloadZoteroPDFs("username", "api_key", "collection_name", "./papers")
Julia Package
using PrismAId
# Download from URL list
PrismAId.download_url_list("path/to/urls.txt")
# Download from Zotero
PrismAId.download_zotero_pdfs("username", "api_key", "collection_name", "./papers")
Downloading from URL Lists
The Download tool supports three input formats for batch downloading:
- Plain text files (.txt): Simple list with one URL per line
- CSV files (.csv): Comma-separated values with automatic column detection
- TSV files (.tsv): Tab-separated values with automatic column detection
Plain Text Format
Create a simple text file with one URL per line:
https://example.com/paper1.pdf
https://doi.org/10.1234/example
https://arxiv.org/pdf/2301.12345.pdf
# This is a comment (ignored)
CSV/TSV Format with Metadata
For CSV or TSV files, the tool uses intelligent column detection with content analysis:
Column Detection Priority:
- URL/Link: BestLink, BestURL, URL, Link, href (prioritizes “best” variants)
- DOI: Automatically converts DOIs to resolvable URLs if no direct URL is found
- Title: ArticleTitle, Article_Title, Paper_Title, Title
- Authors: Authors, Creator, Contributor
- Year: PublicationYear, Publication_Year, Year
- Journal: Prioritized detection to distinguish journal names from database sources:
- High Priority: SourceTitle, Source_Title, Publication_Title, JournalTitle, Journal_Title
- Medium Priority: Journal, Venue, Publication
- Low Priority: Source (with content analysis to distinguish from database names)
- Abstract: Abstract (preserved for future use)
Smart Content Analysis:
- Analyzes sample data to distinguish between journal names and database sources
- Automatically detects when “Source” contains database names (Scopus, PubMed, etc.) vs journal titles
- Prefers more specific column names like “SourceTitle” over generic “Source” when both exist
Example CSV file:
ArticleTitle,Authors,PublicationYear,BestLink,DOI,SourceTitle
"Climate Change Impacts","Smith, J.; Jones, M.",2023,https://example.com/paper1.pdf,10.1234/abc,Nature
"Machine Learning Review","Brown, A.",2024,,10.5678/def,Science
Intelligent Problematic URL Detection
When using CSV/TSV files, the tool automatically detects URLs from platforms that require JavaScript rendering or API tokens to access content. These “problematic URLs” cannot be processed without a browser or authentication, so the tool employs an intelligent fallback strategy:
Detected Problematic Platforms:
- Dimensions.ai (
app.dimensions.ai) - ResearchGate (
researchgate.net) - Academia.edu (
academia.edu) - Semantic Scholar Web UI (
semanticscholar.org/paper/)
Fallback Strategy:
When a problematic URL is detected, the tool automatically:
- First Priority - Use DOI from CSV: If a DOI is available in your CSV file, it will use that instead of the problematic URL
Original URL: https://app.dimensions.ai/details/publication/pub.123456 Available DOI: 10.1234/journal.2023.456 → Uses: https://doi.org/10.1234/journal.2023.456 - Second Priority - Query Crossref API: If no DOI is available in the CSV, the tool searches the Crossref API using the paper’s title, authors, and year to find the correct DOI
Original URL: https://www.researchgate.net/publication/123456789 No DOI in CSV → Searches Crossref with: "Paper Title", "Smith, J.; Jones, M.", "2023" → Finds DOI: 10.1234/journal.2023.456 → Uses: https://doi.org/10.1234/journal.2023.456 - Fallback - Attempt Original URL: If both strategies fail, the tool will still attempt to download from the original URL (though this will likely fail for JavaScript-dependent sites)
Example Log Output:
Row 4: Detected problematic URL (requires browser/API): https://app.dimensions.ai/...
Row 4: No DOI available, searching Crossref...
Crossref match score: 76.51, Title: [Environmental and social life cycle...]
Row 4: Found DOI via Crossref: 10.1016/j.scitotenv.2019.07.270
This intelligent detection saves you from manually replacing problematic URLs and ensures maximum success in downloading papers from your CSV files.
Performance Optimizations
The Download tool includes several performance optimizations for efficient batch downloading:
HTTP/2 and Connection Pooling:
- Uses a single optimized HTTP client with connection pooling across all download requests
- Maintains up to 100 idle connections (10 per host) for connection reuse
- Enables HTTP/2 where supported by the server for multiplexed requests
- Configured timeouts: 60s general, 5 minutes for large PDF downloads
- Automatic gzip compression support
Concurrent Downloads with Smart Rate Limiting:
- Downloads multiple PDFs simultaneously using goroutines and worker pools
- Global concurrency limit: Maximum 25 concurrent downloads system-wide
- Per-host concurrency limit: Maximum 4 concurrent requests per publisher/domain
- Prevents overwhelming individual publishers and reduces 429/403 throttling responses
- Automatically manages connection resources while maximizing throughput
Early Response Validation:
- Validates
Content-Typeheaders before downloading full response body - Checks first 4 bytes for
%PDFsignature to confirm valid PDF files - Aborts quickly on HTML error pages or invalid content to save bandwidth
- Reduces wasted time and resources on non-PDF responses
Intelligent Retry Policy:
- Automatic retry on transient errors (5xx status codes, timeouts, connection resets)
- Respects
Retry-Afterheaders from servers to avoid aggressive retrying - Exponential backoff with jitter (1s, 2s, 4s delays) to prevent retry storms
- Maximum 3 retry attempts per download with smart error classification
- Non-retryable errors (4xx client errors) fail immediately
Unpaywall Fallback for Open Access:
- When downloads fail, automatically searches Unpaywall database as a last resort
- Finds free, legal open access versions of scholarly articles from 50,000+ publishers
- Extracts DOIs from URLs or metadata to query the open access database
- Attempts download from alternative open access repositories when available
- Helps recover papers that might be paywalled at original source but freely available elsewhere
Benefits:
- Significantly faster batch downloads compared to sequential processing
- Respectful downloading that avoids hammering individual publishers
- Faster downloads when processing multiple papers from the same publisher
- Reduced network overhead through connection reuse
- Better performance on modern servers supporting HTTP/2
- Optimized timeouts prevent hanging on slow connections
- Automatic load balancing across different hosts
These optimizations are automatic and require no configuration from users.
Intelligent File Naming
When using CSV/TSV files, the tool generates meaningful filenames using available metadata:
- Format:
[Year]_[FirstAuthorLastName]_[TruncatedTitle].pdf - Example:
2023_Smith_Climate_Change_Impacts.pdf - Falls back to row ID if metadata is insufficient
Download Output Files
The Download tool generates a single comprehensive output file for all input formats:
Single Download Results File
Regardless of input format (plain text, CSV, or TSV), the tool generates:
-
Downloaded PDFs: Saved to the same directory as the input file with intelligent metadata-based naming
-
Download Results File (
[filename]_download.csvor[filename]_download.tsv): A single file containing all information about the download process
For Plain Text URL Lists (urls.txt), the output file contains:
url,downloaded,error_reason,filename
https://doi.org/10.21105/joss.07616,true,,Journal_of_Open_Source_Software.pdf
https://example.com/inaccessible-paper.pdf,false,Download failed or no PDF found,
https://invalid-domain.com/paper.pdf,false,Download failed or no PDF found,
For CSV/TSV Files, the output preserves all original columns and adds three new ones:
Title,Authors,Year,URL,DOI,OtherColumns...,downloaded,error_reason,filename
"Paper One","Smith, J.",2023,https://example.com/1.pdf,10.1234/abc,...,true,,2023_Smith_Paper_One.pdf
"Paper Two","Jones, M.",2024,https://dimensions.ai/...,,...,false,No PDF found,
The three additional columns are:
downloaded:truefor successful downloads,falsefor failureserror_reason: Description of what went wrong (empty for successful downloads)filename: The PDF filename for successful downloads (empty for failures)
This unified approach provides:
- Complete tracking of download status in a single file
- Easy identification of successful vs failed downloads
- Error details for troubleshooting failed downloads
- Preservation of all original metadata
- Integration-friendly format for further processing
The URL list download feature allows you to batch download papers from a text file containing URLs, one per line.
Creating Your URL List
- Create a simple text file (e.g.,
paper_urls.txt) - Add one paper URL per line, for example:
https://arxiv.org/pdf/2303.08774.pdf https://www.science.org/doi/pdf/10.1126/science.1236498 https://www.nature.com/articles/s41586-021-03819-2.pdf - Save the file
Running the Download
Using your preferred method from the Usage Methods section, point the tool to your URL list. For example, with the binary:
./prismaid -download-URL paper_urls.txt
Output
Papers will be downloaded to the current working directory by default. Each paper is saved with a filename derived from its URL. Additionally, a download results file ([filename]_download.csv) is created containing all URLs with their download status, error reasons (if any), and resulting filenames.
Zotero Integration
The Zotero integration allows direct access to papers stored in your Zotero library or group collections.
Getting Your Zotero Credentials
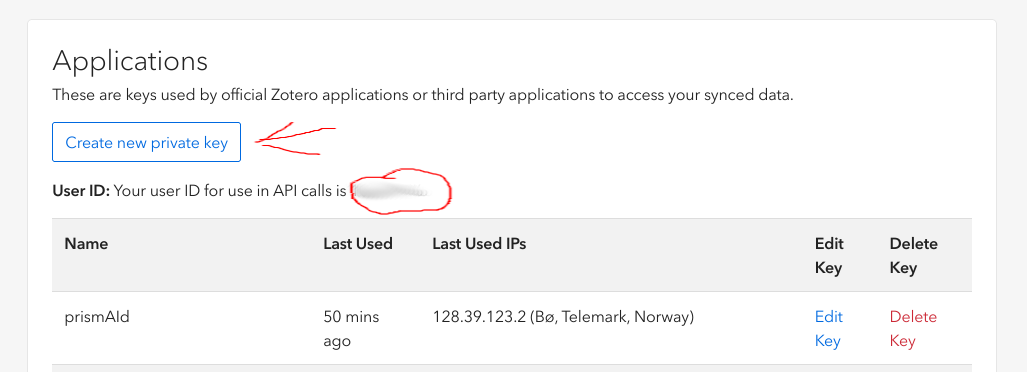
- Find Your User ID:
- Go to the Zotero Settings page
- Navigate to the Security tab, then to the Applications section
- Your user ID is displayed at the top:
- Generate an API Key:
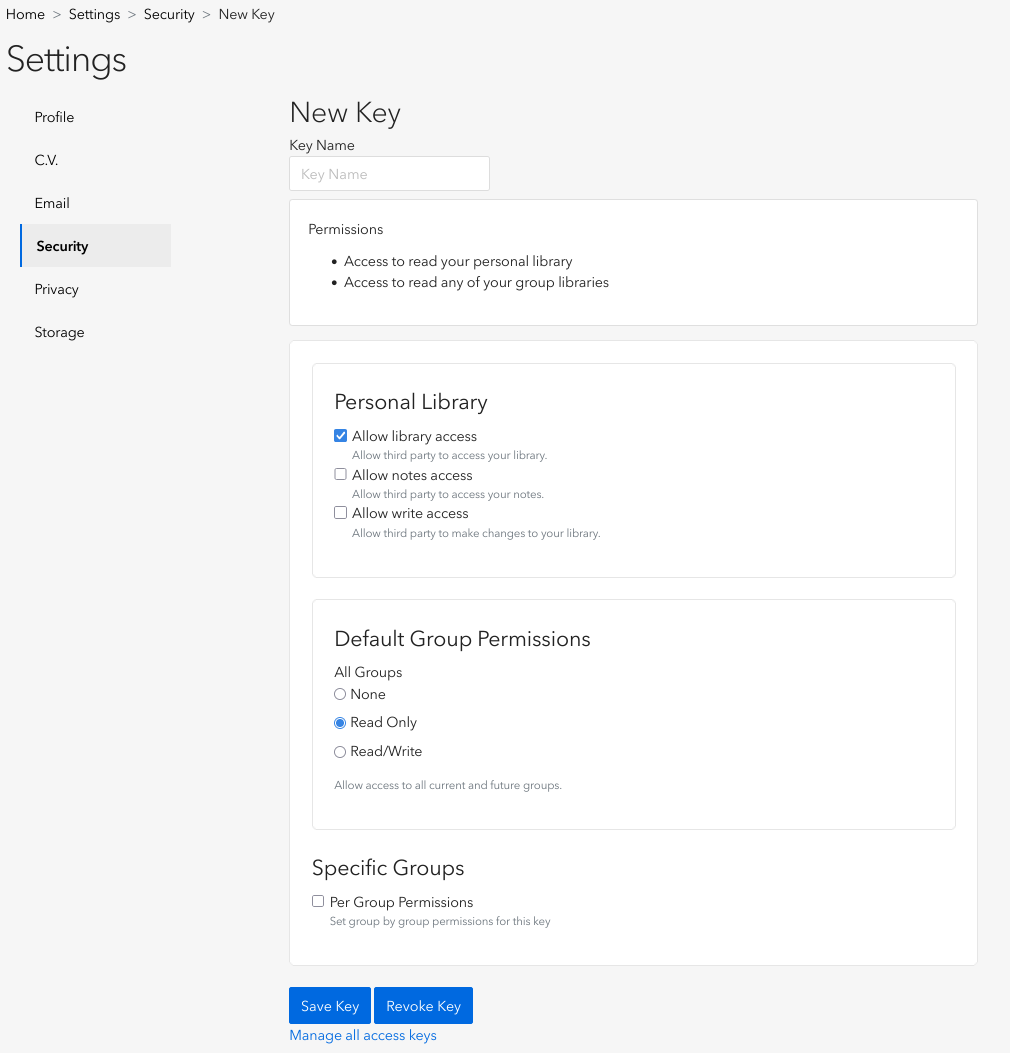
- Click “Create new private key”
- Enable “Allow library access”
- Set permissions to “Read Only” for all groups under “Default Group Permissions”
- Provide a name for the key, such as “prismAId”
- Click “Save Key” and copy your new API key
Specifying Collections and Groups
The collection parameter uses a filesystem-like representation for your Zotero library structure:
- For a top-level collection:
"Collection Name" - For a parent collection with a sub-collection:
"Parent Collection/Sub Collection" - For a group with a collection:
"Group Name/Collection Name"
Creating a Zotero Config File
For the binary method, create a TOML configuration file (e.g., zotero_config.toml):
user = "12345678" # Your Zotero user ID
api_key = "AbCdEfGhIjKlMnOpQrStUv" # Your Zotero API key
group = "Systematic Review/Climate Papers" # Your collection path
Running the Download
Choose your preferred method from the Usage Methods section. For example, with the binary:
./prismaid -download-zotero zotero_config.toml
Or with Python:
import prismaid
prismaid.download_zotero_pdfs("12345678", "AbCdEfGhIjKlMnOpQrStUv", "Systematic Review/Climate Papers")
Best Practices
To get the most out of the Download tool:
- Organize before downloading:
- When using Zotero, organize papers into collections based on their relevance to your review
- For URL lists, verify all URLs are accessible before batch downloading
- Use the generated output files (failed URLs log, enhanced CSV) to track and retry failed downloads
- Use CSV/TSV format for problematic URLs:
- If your URL list contains links from Dimensions.ai, ResearchGate, Academia.edu, or Semantic Scholar, use CSV/TSV format instead of plain text
- Include metadata columns (Title, Authors, Year, DOI) to enable automatic Crossref resolution
- The tool will intelligently detect and resolve problematic URLs, significantly improving download success rates
- Optimize for batch downloads:
- The tool automatically uses HTTP/2 and connection pooling for better performance
- Group downloads from the same publisher/domain for maximum connection reuse benefits
- Large CSV files benefit most from the connection pooling optimizations
- Check for duplicates:
- Zotero can help identify duplicate entries before downloading
- Use consistent file naming in URL lists to avoid duplicate downloads
- Verify accessibility:
- Ensure you have access rights to all papers before downloading
- Some journals may require institutional access or subscriptions
- Structure your downloads:
- Use separate output directories for different paper categories
- Consider naming conventions that will help with the next workflow steps
- Batch processing:
- For large reviews, consider downloading in batches to manage resources
- This approach also allows for quality checks along the way
Troubleshooting
Common Issues with URL Downloads
- Invalid URLs: Ensure all URLs in your list are properly formatted and accessible
- Access Restrictions: Some papers may require login credentials or institutional access
- Network Issues: Check your internet connection if downloads fail consistently
- Timeout Errors: Large files may cause timeout issues; try increasing timeout settings if available
- JavaScript-dependent URLs: URLs from Dimensions.ai, ResearchGate, Academia.edu, or Semantic Scholar web UI cannot be accessed without a browser. Solution: Use CSV/TSV format with metadata to enable automatic DOI resolution via Crossref
- Crossref API Limitations: The Crossref API may occasionally be slow or return no results for obscure papers. The tool will fall back to attempting the original URL in such cases
Common Issues with Zotero Integration
- Authentication Errors:
- Verify your user ID and API key are correct
- Ensure the API key has appropriate permissions
- Check that the API key hasn’t expired
- Collection Not Found:
- Verify the collection/group path exists and uses the correct format
- Collection names are case sensitive
- Check for typos in the collection path
- Missing PDFs in Zotero:
- Some entries in Zotero may not have attached PDFs
- The tool can only download papers that have PDF attachments in Zotero
- Rate Limiting:
- Zotero API has rate limits; if you receive 429 errors, slow down your requests
- For large collections, consider downloading in smaller batches
Workflow Integration
The Download tool is designed to fit seamlessly into your systematic review workflow:
- Literature Search:
- Search databases and identify potentially relevant papers
- Export search results to CSV or reference manager
- Screening (Screening Tool):
- Filter out duplicates, wrong languages, and irrelevant article types
- Create a refined list of papers to acquire
- Literature Acquisition (Download Tool):
- Download only the screened papers from Zotero collections or URL lists
- If using CSV/TSV exports from databases, benefit from automatic problematic URL detection and DOI resolution
- Use the enhanced CSV with download status to track acquisition progress
- Retry failed downloads using the failed URLs log or enhanced CSV
- Organize papers in a structured directory with intelligent metadata-based naming
- Format Conversion (Convert Tool):
- Convert downloaded papers to text format for analysis
- Systematic Review (Review Tool):
- Process papers and extract structured information
By automating the literature acquisition step with the Download tool, you can significantly reduce the time and effort required for systematic reviews while ensuring a comprehensive and well-organized collection of literature.