Using prismAId
Page Contents:
- Section 1: ‘Project’ Details: reference guide to all entries in the first section of the project configuration
- Section 2: ‘Prompt’ Details: instructions on configuring prompts for information extraction
- Section 3: ‘Review’ Details: information content to be extracted and reviewed
- Advanced Features: how to leverage debugging, validation, and integration with other tools
Prepare a project configuration file in TOML, following the three-section structure, explanations, and recommendations provided in the template.toml and below. Alternatively, you can use the terminal-based initialization option (-init in binaries) or the web-based tool on the Review Configurator page.
Section 1, introduced below, focuses on essential project settings. Sections 2 and 3 cover prompt design and follow in sequence, while advanced features in Section 1 are discussed at the end of this page.
Section 1: ‘Project’ Details
Project Information
[project]
name = "Use of LLM for Systematic Review"
author = "John Doe"
version = "1.0"
- The
[project]section contains basic project information:name: Project title.author: Project author.version: Configuration version.
Configuration Details
[project.configuration]
input_directory = "/path/to/txt/files"
input_conversion = ""
results_file_name = "/path/to/save/results"
output_format = "json"
log_level = "low"
duplication = "no"
cot_justification = "no"
summary = "no"
[project.configuration] specifies execution settings:
input_directory: Location of.txtfiles for review.input_conversion: Non-active if left empty (default) or key removed. Enable withpdf,docx,html, or as a comma-separated list (e.g.,pdf,docx).results_file_name: Path to save results.output_format:csvorjson.log_level: Sets log detail:low: Minimal logging, essential output only (default).medium: Logs details sent to stdout.high: Logs are saved in a file.
duplication: Controls review duplication for debugging:no: Default.yes: Files in the input directory are duplicated, reviewed, and removed before the program concludes.
cot_justification: Adds justification logs:no: Default.yes: Logs justification per manuscript, saved in the same directory.
summary: Enables summary logging:no: Deafult.yes: A summary is generated for each manuscript and saved in the same directory.
Zotero Section
[project.zotero]
user = "12345678"
api_key = "fdjkdfnjhfd4556"
group = "My Group/My Collection"
[project.zotero]contains the parameters needed to integrate Zotero collections or groups into your review process. Omitting this section or leaving its fileds empty (i.e.,"") will disable Zotero integration. See details also below.
Parameters:
user: Your Zotero user ID, which can be found by visiting Zotero Settings. Look for “User ID for use in API calls” under your API keys.api_key: A private API key for accessing the Zotero API. Create one by going to Zotero Settings and selecting “Create new private key”. When creating the key, ensure that you enable “Allow library access” and set the permissions to “Read Only” for all groups under “Default Group Permissions”.group: The name of the collection or group containing the documents you wish to review. If the collection or group is nested, represent the hierarchy using a forward slash (/), e.g., “Parent Collection/Sub Collection”.
LLM Configuration
[project.llm]
[project.llm.1]
provider = "OpenAI"
api_key = ""
model = ""
temperature = 0.2
tpm_limit = 0
rpm_limit = 0
[project.llm]specifies model configurations for review execution. At least one model is required. When multiple models are configured, results will represent an ‘ensemble’ analysis.
The [project.llm.#] fields manage LLM usage:
provider: Supported providers areOpenAI,GoogleAI,Cohere, andAnthropic.api_key: Define project-specific keys here, or leave empty to default to environment variables.model: select model:- Leave blank
''for cost-efficient automatic model selection. - OpenAI: Models include
gpt-4o-mini,gpt-4o,gpt-4-turbo,gpt-3.5-turbo. - GoogleAI: Choose from
gemini-1.5-flash,gemini-1.5-pro,gemini-1.0-pro. - Cohere: Options are
command-r-plus,command-r,command-light,command. - Anthropic: Includes
claude-3-5-sonnet,claude-3-5-haiku,claude-3-opus,claude-3-sonnet,claude-3-haiku. - DeepSeek: Provides
deepseek-chat, version 3.
- Leave blank
temperature: Controls response variability (range: 0 to 1 for most models); lower values increase consistency.tpm_limit: Defines maximum tokens per minute. Default is0(no delay). Use a non-zero value based on your provider TPM limits (see Rate Limits in Advanced Features below).rpm_limits: Sets maximum requests per minute. Default is0(no limit). See provider’s RPM restrictions in Advanced Features below.
Supported Models
Each model has specific limits for input size and costs, as summarized below:
| Model | Maximum Input Tokens | Cost of 1M Input Tokens |
|---|---|---|
| OpenAI | ||
| GPT-4o Mini | 128,000 | $0.15 |
| GPT-4o | 128,000 | $5.00 |
| GPT-4 Turbo | 128,000 | $10.00 |
| GPT-3.5 Turbo | 16,385 | $0.50 |
| GoogleAI | ||
| Gemini 1.5 Flash | 1,048,576 | $0.15 |
| Gemini 1.5 Pro | 2,097,152 | $2.50 |
| Gemini 1.0 Pro | 32,760 | $0.50 |
| Cohere | ||
| Command R7B | 128,000 | $0.0375 |
| Command R+ | 128,000 | $2.50 |
| Command R | 128,000 | $0.15 |
| Command Light | 4,096 | $0.30 |
| Command | 4,096 | $1.00 |
| Anthropic | ||
| Claude 3.5 Sonnet | 200,000 | $3.00 |
| Claude 3.5 Haiku | 200,000 | $1.00 |
| Claude 3 Sonnet | 200,000 | $3.00 |
| Claude 3 Opus | 200,000 | $15.00 |
| Claude 3 Haiku | 200,000 | $0.25 |
| DeepSeek | ||
| DeepSeek-V3 | 64,000 | $0.14 |
Section 2: ‘Prompt’ Details
Section 2 and 3 of the project configuration file define the prompts that guide AI models in extracting targeted information. This section is central to a review project, with prismAId’s robust design enabling the tool’s Open Science benefits.
The [prompt] section breaks down the prompt structure into essential components to ensure accurate data extraction and minimize potential misinterpretations.
Rationale
- This section provides explicit instructions and context for the AI model.
- The prompt consists of structured elements:
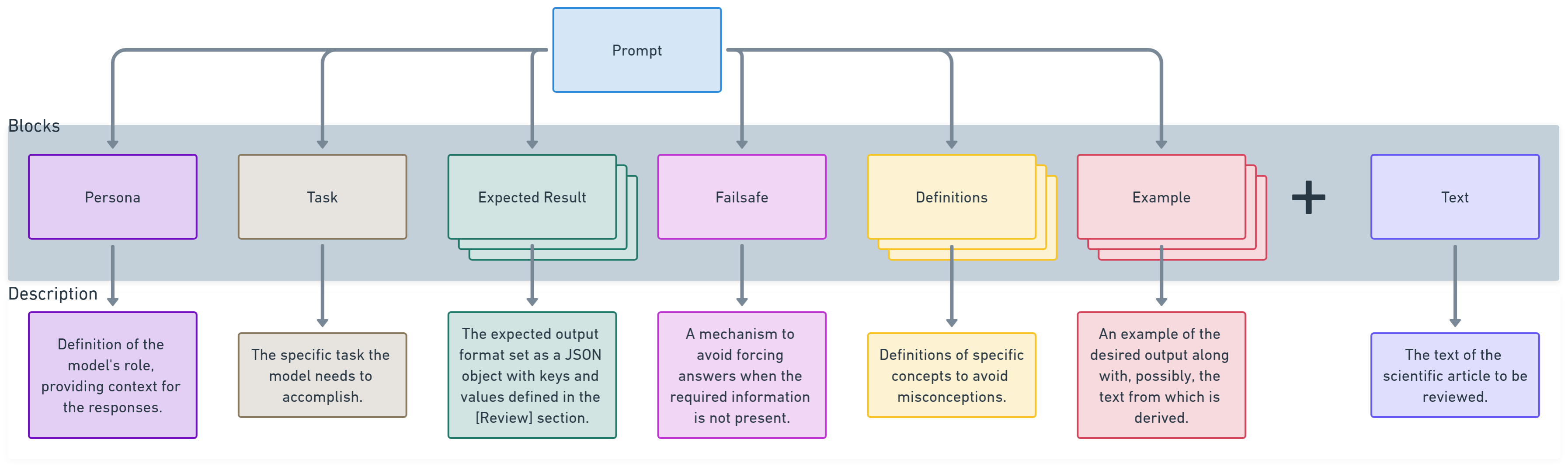
- Each component clarifies the model’s role, task, and expected output, reducing ambiguity.
- Definitions and examples enhance clarity, while a failsafe mechanism prevents forced responses if information is absent.
[prompt]
persona = "You are an experienced scientist working on a systematic review of the literature."
task = "You are asked to map the concepts discussed in a scientific paper attached here."
expected_result = "You should output a JSON object with the following keys and possible values: "
failsafe = "If the concepts neither are clearly discussed in the document nor they can be deduced from the text, respond with an empty '' value."
definitions = "'Interest rate' is the percentage charged by a lender for borrowing money or earned by an investor on a deposit over a specific period, typically expressed annually."
example = ""
This structured approach increases consistency, reduces model hallucinations, and facilitates precise information extraction in line with research objectives.
Entry Details
persona:- Example: “You are an experienced scientist working on a systematic review of the literature.”
- Purpose: Sets the model’s role, providing context to guide responses appropriately.
task:- Example: “You are asked to map the concepts discussed in a scientific paper attached here.”
- Purpose: Defines the model’s specific task, clarifying its objectives.
expected_result:- Example: “You should output a JSON object with the following keys and possible values.”
- Purpose: Specifies the output format, ensuring structured responses.
failsafe:- Example: “If the concepts neither are clearly discussed in the document nor deducible, respond with an empty ‘’ value.”
- Purpose: Prevents the model from generating forced responses when information is missing, enhancing accuracy.
definitions:- Example: “‘Interest rate’ is the percentage charged by a lender for borrowing money.”
- Purpose: Provides precise definitions to reduce misinterpretations.
example:- Example: “For example, given the text ‘A recent global analysis based on ARIMA models suggests that wind energy products return is 4.3% annually.’ the output JSON object could be: {“interest rate”: 4.3, “regression models”: “yes”, “geographical scale”: “world”}”
- Purpose: Offers a sample output to further clarify expectations, guiding the model toward accurate responses.
Section 3: ‘Review’ Details
The [review] section specifies the information to be extracted from the text, defining the JSON output structure with keys and their possible values.
Rationale
- This section serves as a knowledge map to guide the extraction process.
- Each item includes:
key: A concept or topic of interest.values: Possible values for that key.
- This structure ensures consistency and adherence to the schema. You may add as many review items as needed.
[review]
[review.1]
key = "interest rate"
values = [""]
[review.2]
key = "regression models"
values = ["yes", "no"]
[review.3]
key = "geographical scale"
values = ["world", "continent", "river basin"]
Entry Details
[review]:- Header indicating the start of review items, defining the structure of the knowledge map.
[review.1]:- Represents the first item to review.
key: “interest rate”- The concept or topic to be extracted.
values:[""]- An empty string allows any value.
[review.2]:- Represents the second item to review.
key: “regression models”values:["yes", "no"]- Allows “yes” or “no” as binary options.
[review.3]:- Represents the third item to review.
key: “geographical scale”values:["world", "continent", "river basin"]- Specifies scale options for analysis.
Advanced Features
Debugging & Validation
In Section 1 of the project configuration, three parameters support project development and prompt testing:
log_level: Controls logging detail with options:low(default),medium, andhigh.duplication: Enables prompt duplication for consistency testing (no/yes).cot_justification: Activates Chain-of-Thought justifications (no/yes).
Increasing log_level beyond low provides detailed API response insights, visible on the terminal (medium) or saved to a log file (high).
Duplication helps validate prompt clarity by duplicating reviews. Inconsistent outputs across duplicates indicate unclear prompts. Costs are displayed based on duplication settings.
CoT Justification generates a .txt file per manuscript, logging the model’s thought process, responses, and relevant passages. Example output:
- **clustering**: "no" - The text does not mention any clustering techniques or grouping of data points based on similarities.
- **copulas**: "yes" - The text explicitly mentions the use of copulas to model the joint distribution of multiple flooding indicators (maximum soil moisture, runoff, and precipitation). "The multidimensional representation of the joint distributions of relevant hydrological climate impacts is based on the concept of statistical copulas [43]."
- **forecasting**: "yes" - The text explicitly mentions the use of models to predict future scenarios of flooding hazards and damage. "Future scenarios use hazard and damage data predicted for the period 2018–2100."
Rate Limits
Model usage limits can be managed with two main parameters set in [project.llm] section of the project configuration:
tpm_limit: Sets a maximum for tokens processed per minute.rpm_limit: Sets a maximum for requests per minute.
Defaults for both are 0, meaning no delays are applied. For non-zero values, prismAId enforces delays to meet specified limits.
Note: Daily request limits are not automatically enforced, so manual monitoring is required for users with daily limits.
OpenAI Rate Limits
(August 2024, tier 1 users)
| Model | RPM | RPD | TPM | Batch Queue Limit |
|---|---|---|---|---|
| gpt-4o | 500 | - | 30,000 | 90,000 |
| gpt-4o-mini | 500 | 10,000 | 200,000 | 2,000,000 |
| gpt-4-turbo | 500 | - | 30,000 | 90,000 |
| gpt-3.5-turbo | 3,500 | 10,000 | 200,000 | 2,000,000 |
GoogleAI Rate Limits
(October 2024)
Free Tier:
| Model | RPM | RPD | TPM |
|---|---|---|---|
| Gemini 1.5 Flash | 15 | 1,500 | 1,000,000 |
| Gemini 1.5 Pro | 2 | 50 | 32,000 |
| Gemini 1.0 Pro | 15 | 1,500 | 32,000 |
Pay-as-you-go:
| Model | RPM | RPD | TPM |
|---|---|---|---|
| Gemini 1.5 Flash | 2000 | - | 4,000,000 |
| Gemini 1.5 Pro | 1000 | - | 4,000,000 |
| Gemini 1.0 Pro | 360 | 30,000 | 120,000 |
Cohere Rate Limits
Cohere production keys have no limit, but trial keys are limited to 20 API calls per minute.
Anthropic Rate Limits
(November 2024, tier 1 users)
| Model | RPM | TPM | TPD |
|---|---|---|---|
| Claude 3.5 Sonnet | 50 | 40,000 | 1,000,000 |
| Claude 3.5 Haiku | 50 | 50,000 | 5,000,000 |
| Claude 3 Opus | 50 | 20,000 | 1,000,000 |
| Claude 3 Sonnet | 50 | 40,000 | 1,000,000 |
| Claude 3 Haiku | 50 | 50,000 | 5,000,000 |
DeepSeek Rate Limits
DeepSeek does not impose rate limits.
Note: To ensure adherence to provider limits, users should manually set the lowest applicable tpm and rpm values in the configuration, as prismAId does not enforce automatic checks.
Cost Minimization
In Section 1 of the project configuration:
model: Leaving this field empty ('') enables automatic selection of the most cost-efficient model from the chosen provider. This may result in varying models for manuscripts based on length and token limits.
How Costs are Computed
Cost minimization considers both the cost of using the model for each unit (token) of input and the total number of input tokens, because more economical models may have stricter limits on how much data they can handle.
- Tokenization Libraries: prismAId uses libraries specific to each provider:
- OpenAI’s cost minimization uses the Tiktoken library.
- Google’s token minimization uses the CountTokens API.
- Cohere uses its API.
- Anthropic approximates token counts via OpenAI’s tokenizer.
- DeepSeek approximates token counts via OpenAI’s tokenizer.
Concise prompts are cost-efficient. Check costs on the provider dashboards: OpenAI, Google AI, Cohere, Anthropic, and DeepSeek.
Note: Cost estimates are approximate and subject to change. Users with strict budgets should verify all costs thoroughly before conducting reviews.
Ensemble Review
Specifying multiple LLMs enables an ‘ensemble’ review, allowing result validation and uncertainty quantification. You can select multiple models from one or more providers, configuring each with specific parameters.
To set up an ensemble review in the [project.llm] section, for instance with models from five different providers, use:
[project.llm]
[project.llm.1]
provider = "OpenAI"
api_key = ""
model = "gpt-4o-mini"
temperature = 0.01
tpm_limit = 0
rpm_limit = 0
[project.llm.2]
provider = "GoogleAI"
api_key = ""
model = "gemini-1.5-flash"
temperature = 0.01
tpm_limit = 0
rpm_limit = 0
[project.llm.3]
provider = "Cohere"
api_key = ""
model = "command-r"
temperature = 0.01
tpm_limit = 0
rpm_limit = 0
[project.llm.4]
provider = "Anthropic"
api_key = ""
model = "claude-3-haiku"
temperature = 0.01
tpm_limit = 0
rpm_limit = 0
[project.llm.5]
provider = "DeepSeek"
api_key = ""
model = "deepseek-chat"
temperature = 0.01
tpm_limit = 0
rpm_limit = 0
Zotero Integration
The tool can automatically download and process literature from your specified Zotero collections or groups.
Configuration
To enable this, you must configure access credentials and group structure in the [project.zotero] section, for example:
[project.zotero]
user = "12345678"
api_key = "fdjkdfnjhfd4556"
group = "My Group/My Sub Collection"
To get your credentials, go to the Zotero Settings page, navigate to the Security tab, and then to the Applications section. You will find your user ID and the button to generate an API key, as shown below:
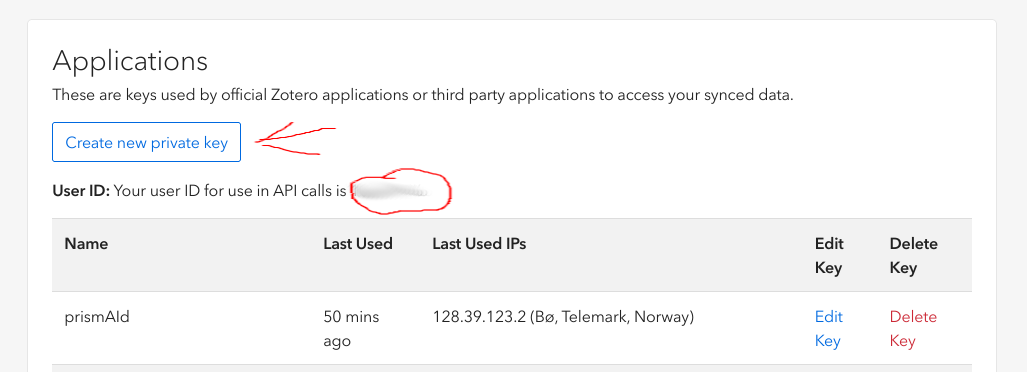
When creating a new API key, you must enable “Allow library access” and set the permissions to “Read Only” for all groups under “Default Group Permissions”. You must also provide a name for the key, such as “test” or “prismaid”.
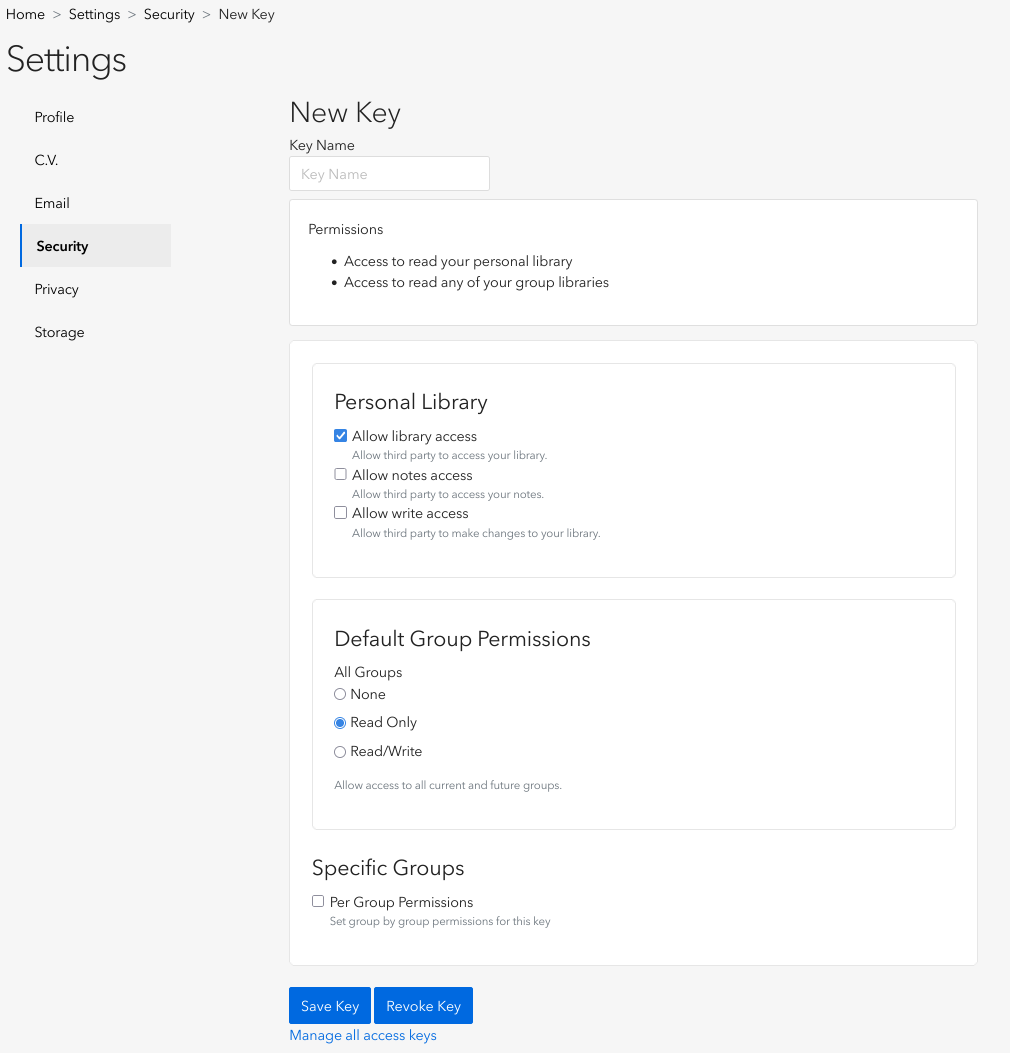
Once you have added your Zotero API credentials to your project configuration in the [project.zotero] section (fields user and api_key), you must specify the group or collection to review in the group field. This field uses a filesystem-like representation for the group and collection structure of your Zotero library.
For instance, if you have a parent collection called “My Collection” and a nested sub-collection called “My Sub Collection” inside that parent collection, you should specify "My Collection/My Sub Collection" for the group field. Similarly, if you have a group called “My Group” and within that a collection called “My Sub Collection”, you should specify "My Group/My Sub Collection" for the group field.
All PDFs in the selected collection or group will be copied into a zotero subdirectory within the directory you specified in the [project.configuration] section to store the results_file_name. Then, prismAId will convert them into text files and run the review process.
The manuscript files are stored locally and are available for inspection and further cleaning and analysis without the need to connect to the Zotero API again.
Review Workflow Integration
Zotero is a powerful and open-source reference management system designed to help you store, organize, and share your literature. You can structure your manuscripts and references using either collections or groups.
-
Collections are private and accessible only to the user who creates them. For step-by-step instructions on creating collections, refer to the University of Ottawa Library’s guide.
-
Groups allow multiple users to access and collaborate on shared references, making them ideal for teamwork and collaborative research. To learn how to create a group, follow the University of Ottawa Library’s guide.
In the workflow of a systematic literature review, following any protocol, a Zotero collection or group is the perfect place to store the downloaded manuscripts after identifying them through literature search engines and a carefully defined selection query.
The integration of Zotero with prismAId supports the next step in the workflow: manuscripts are automatically converted and then passed to LLMs for analysis and information extraction.
Once the literature to be reviewed is defined, the Zotero integration only needs to be activated once, as all manuscripts are downloaded and stored in the zotero subdirectory. Subsequent analyses and refinements can be performed on the downloaded texts without requiring further connections to the Zotero API.
To disable the Zotero integration, simply leave its fields empty in the [project.zotero] section of the project configuration.
Warning
ATTENTION: The Zotero integration automatically converts PDFs into text using the same methods as those activated by the input_conversion field of [project.configuration]. However, due to the inherent limitations of the PDF format, these conversions might be imperfect. Therefore, both for input_conversion of PDF documents and Zotero integration, please manually check any converted manuscripts for completeness before further processing.